Find the Moving Average of This Year Agains the Avrage of the Last G Years
In this article, we will be looking at how to calculate the moving average in a pandas DataFrame. Moving Average is computing the boilerplate of data over a period of time. The moving average is also known as the rolling mean and is calculated by averaging information of the fourth dimension series within k periods of fourth dimension.
There are three types of moving averages:
- Simple Moving Boilerplate (SMA)
- Exponential Moving Average (EMA)
- Cumulative Moving Average(CMA)
The link to the data used is RELIANCE.NS_
Elementary Moving Average (SMA)
A simple moving average tells us the unweighted mean of the previous K data points. The more the value of G the more smooth is the bend, but increasing Yard decreases accuracy. If the data points are p1,ptwo, . . . , pn and so nosotros summate the simple moving average.
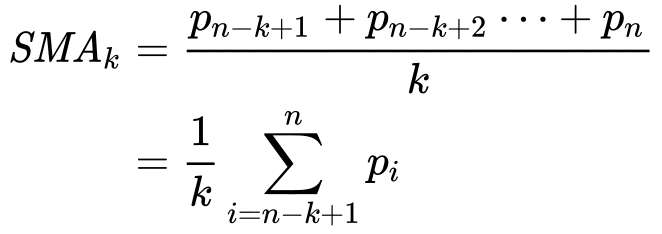
In Python, we can calculate the moving average using .rolling() method. This method provides rolling windows over the data, and we tin can use the hateful function over these windows to calculate moving averages. The size of the window is passed as a parameter in the role .rolling(window).
At present permit's run into an case of how to calculate a simple rolling hateful over a menstruation of thirty days.
Step 1: Importing Libraries
Python3
import pandas equally pd
import numpy equally np
import matplotlib.pyplot every bit plt
plt.style.utilize( 'default' )
% matplotlib inline
Step 2: Importing Data
To import information nosotros will use pandas .read_csv() office.
Python3
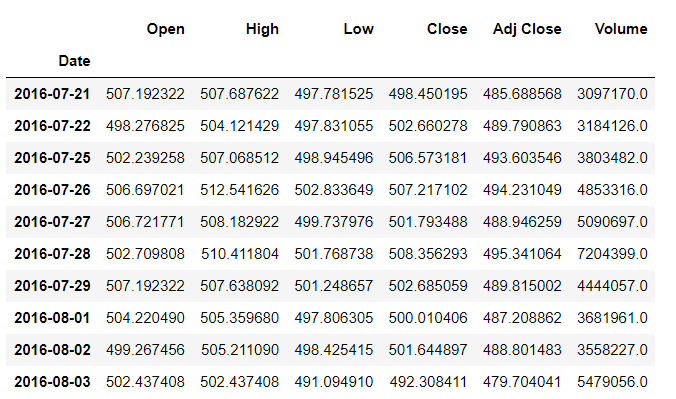
reliance = pd.read_csv( 'RELIANCE.NS.csv' , index_col = 'Date' ,
parse_dates = Truthful )
reliance.head()
Output:
Step 3: Computing Simple Moving Average
To summate SMA in Python we will employ Pandas dataframe.rolling() function that helps us to make calculations on a rolling window. On the rolling window, we volition use .mean() function to calculate the mean of each window.
Syntax: DataFrame.rolling(window, min_periods=None, heart=False, win_type=None, on=None, axis=0).mean()
Parameters :
- window : Size of the window. That is how many observations we take to accept for the calculation of each window.
- min_periods : Least number of observations in a window required to have a value (otherwise result is NA).
- centre : It is used to set the labels at the eye of the window.
- win_type : Information technology is used to set the window type.
- on : Datetime column of our dataframe on which we accept to summate rolling mean.
- axis : integer or string, default 0
Python3
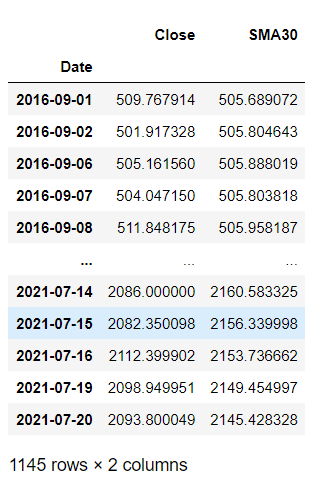
reliance = reliance[ 'Close' ].to_frame()
reliance[ 'SMA30' ] = reliance[ 'Close' ].rolling( 30 ).mean()
reliance.dropna(inplace = true)
reliance
Output:
Step 4: Plotting Simple Moving Averages
Python3
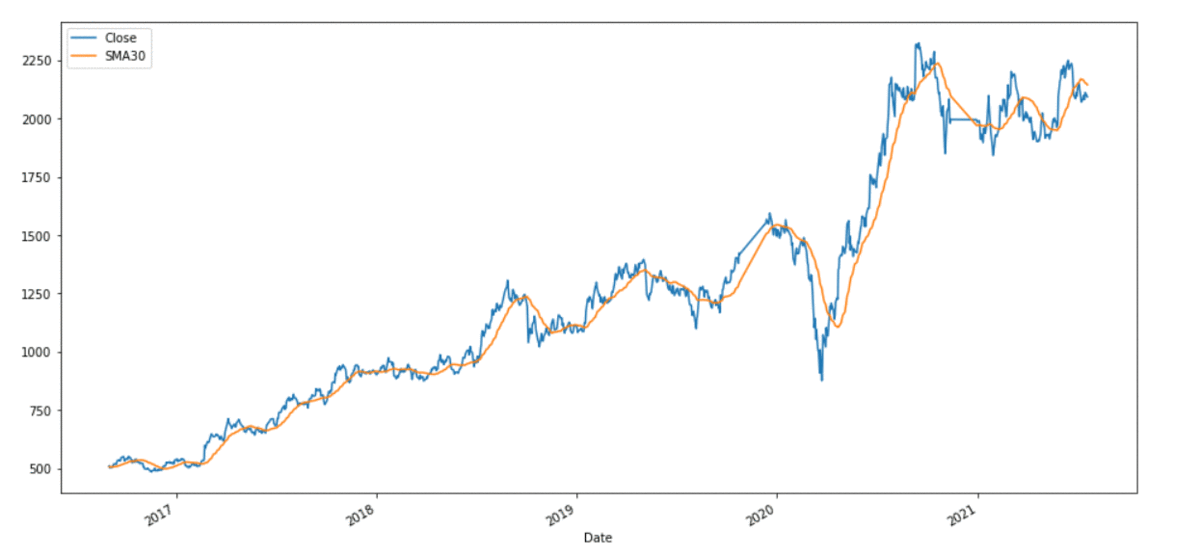
reliance[[ 'Shut' , 'SMA30' ]].plot(label = 'RELIANCE' ,
figsize = ( 16 , 8 ))
Output:
Cumulative Moving Average (CMA)
The Cumulative Moving Boilerplate is the hateful of all the previous values up to the current value. CMA of dataPoints ten1, ten2 ….. at time t tin can exist calculated as,
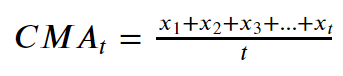
While calculating CMA we don't have any fixed size of the window. The size of the window keeps on increasing as time passes. In Python, we can calculate CMA using .expanding() method. At present we volition see an case, to calculate CMA for a period of 30 days.
Stride ane: Importing Libraries
Python3
import pandas as pd
import numpy every bit np
import matplotlib.pyplot as plt
plt.manner.use( 'default' )
% matplotlib inline
Step 2: Importing Data
To import information we will use pandas .read_csv() role.
Python3
reliance = pd.read_csv( 'RELIANCE.NS.csv' ,
index_col = 'Date' ,
parse_dates = True )
reliance.head()
Stride 3: Calculating Cumulative Moving Average
To calculate CMA in Python we will employ dataframe.expanding() part. This method gives us the cumulative value of our aggregation function (mean in this example).
Syntax: DataFrame.expanding(min_periods=ane, heart=None, axis=0, method='single').mean()
Parameters:
- min_periods : int, default 1 . To the lowest degree number of observations in a window required to have a value (otherwise effect is NA).
- center : bool, default False . It is used to fix the labels at the middle of the window.
- axis : int or str, default 0
- method : str {'single', 'table'}, default 'single'
Python3
reliance = reliance[ 'Close' ].to_frame()
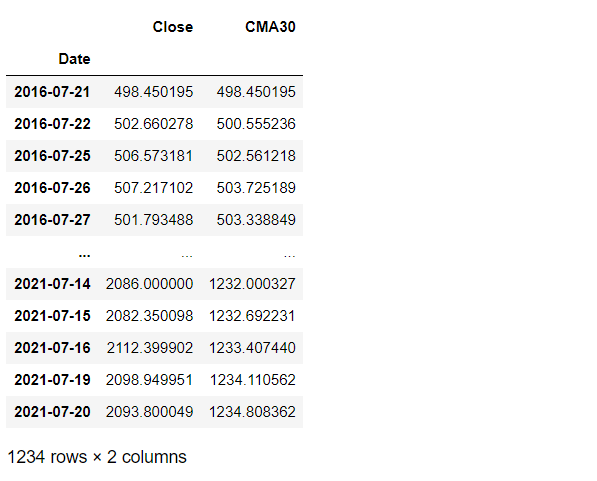
reliance[ 'CMA30' ] = reliance[ 'Close' ].expanding().hateful()
reliance
Output:
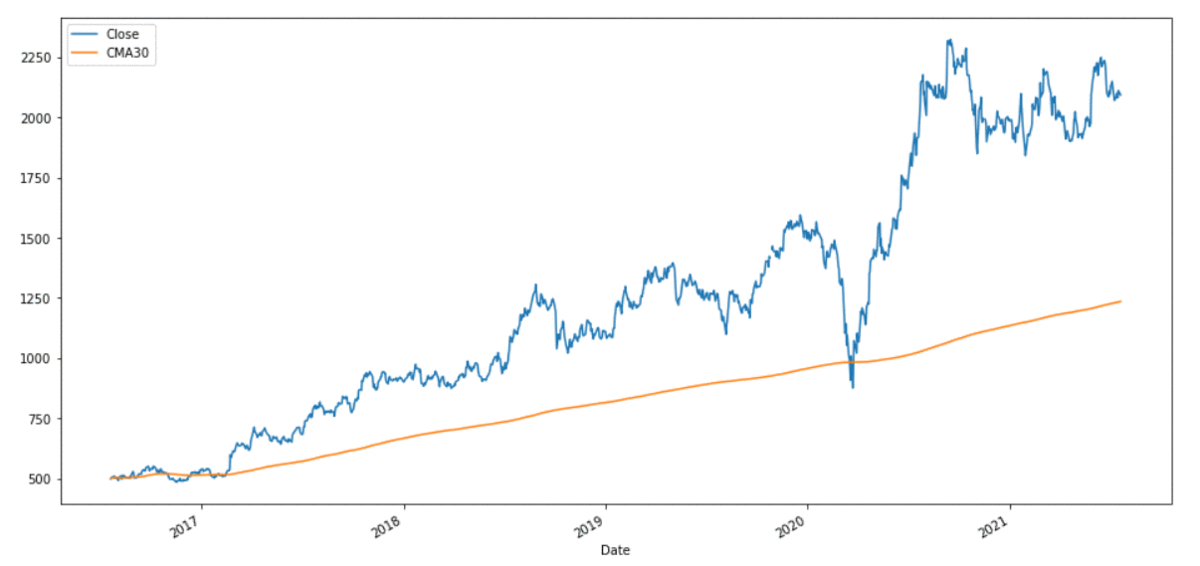
Step 4: Plotting Cumulative Moving Averages
Python3
reliance[[ 'Close' , 'CMA30' ]].plot(label = 'RELIANCE' ,
figsize = ( 16 , 8 ))
Output:
Exponential moving average (EMA):
Exponential moving average (EMA) tells us the weighted mean of the previous Thousand data points. EMA places a greater weight and significance on the most recent data points. The formula to calculate EMA at the time period t is:
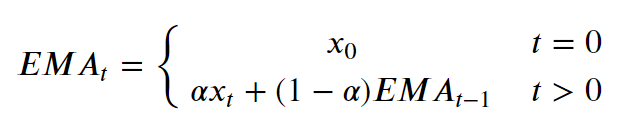
where 10t is the value of ascertainment at fourth dimension t & α is the smoothing factor. In Python, EMA is calculated using .ewm() method. We can pass span or window every bit a parameter to .ewm(span = ) method.
Now we volition be looking at an example to calculate EMA for a menstruation of 30 days.
Footstep 1: Importing Libraries
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot every bit plt
plt.style.use( 'default' )
% matplotlib inline
Footstep 2: Importing Data
To import data we will apply pandas .read_csv() function.
Python3
reliance = pd.read_csv( 'RELIANCE.NS.csv' ,
index_col = 'Date' ,
parse_dates = Truthful )
reliance.head()
Output:
Step 3: Calculating Exponential Moving Average
To calculate EMA in Python nosotros use dataframe.ewm() function. It provides united states exponentially weighted functions. We will be using .mean() office to calculate EMA.
Syntax: DataFrame.ewm(com=None, span=None, halflife=None, alpha=None, min_periods=0, adjust=True, ignore_na=Fake, axis=0, times=None).mean()
Parameters:
- com : float, optional . Information technology is the decay in terms of center of mass.
- bridge : float, optional . It is the disuse in terms of span.
- halflife : float, str, timedelta, optional . Information technology is the disuse in terms of halflife.
- blastoff : bladder, optional . It is the smoothing cistron having value between 0 and 1 , i inclusive .
- min_periods : int, default 0. Least number of observations in a window required to have a value (otherwise result is NA).
- adjust : bool, default True . Divide by decaying aligning factor in first periods to business relationship for imbalance in relative weightings (viewing EWMA as a moving boilerplate)
- ignore_na : Ignore missing values when calculating weights; specify True to reproduce pre-0.15.0 beliefs.
- axis : The axis to use. The value 0 identifies the rows, and ane identifies the columns.
Python3
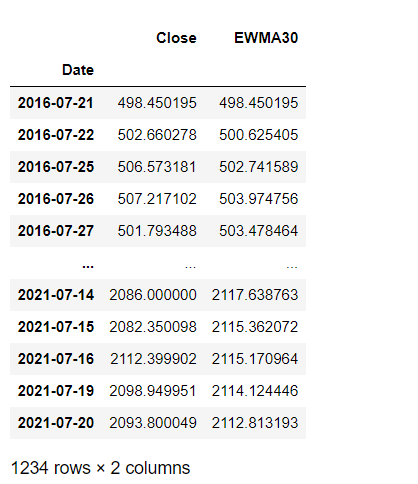
reliance = reliance[ 'Shut' ].to_frame()
reliance[ 'EWMA30' ] = reliance[ 'Close' ].ewm(span = 30 ).mean()
reliance
Output:
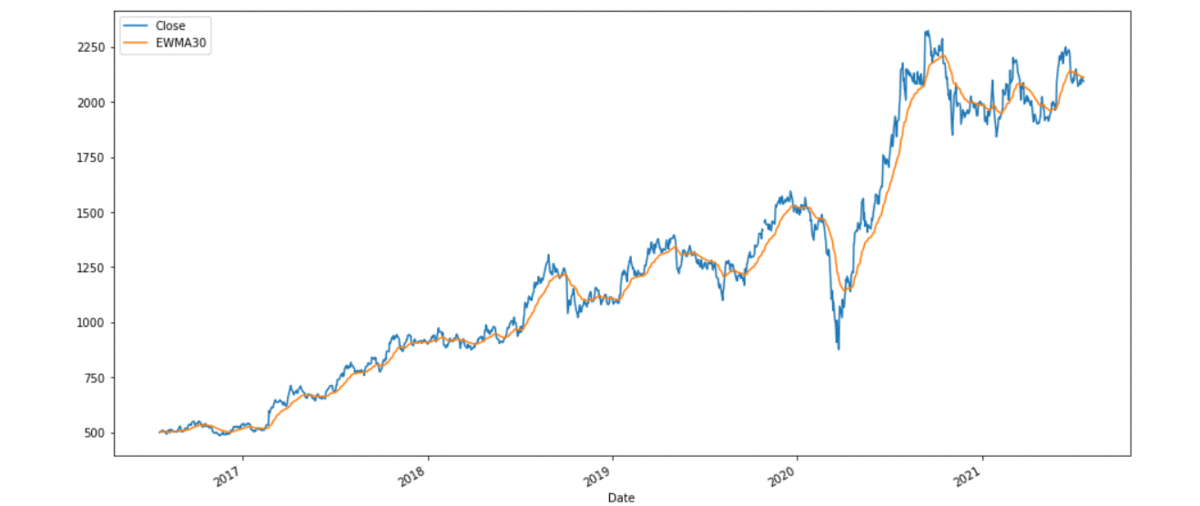
Step iv: Plotting Exponential Moving Averages
Python3
reliance[[ 'Close' , 'EWMA30' ]].plot(characterization = 'RELIANCE' ,
figsize = ( xvi , 8 ))
Output:
reichertthenery49.blogspot.com
Source: https://www.geeksforgeeks.org/how-to-calculate-moving-average-in-a-pandas-dataframe/
0 Response to "Find the Moving Average of This Year Agains the Avrage of the Last G Years"
Post a Comment